QCar2 Autonomous Driving with Natural Language
Vision-Language-Action Model for Intelligent Vehicle Control
Demonstration
Demonstration of QCar2 autonomous driving with natural language command processing. The vehicle navigates the QLabs environment using the SimLingo Vision-Language-Action model, responding to real-time commands while generating natural language commentary explaining its driving decisions.
Project Overview
This project adapts the SimLingo Vision-Language-Action (VLA) model from the CARLA simulator to Quanser's QCar2 platform in QLabs simulation. SimLingo is a state-of-the-art vision-language model for autonomous driving that uses the InternVL2-1B backbone to predict driving waypoints from camera images, target points, and optional natural language instructions.
The system enables autonomous vehicles to understand and execute natural language commands while providing real-time explanations of driving decisions. By integrating computer vision with natural language processing, this research advances the field of intelligent vehicle systems beyond mechanical automation toward truly intelligent robotic behavior.
The complete pipeline processes camera input through JPEG compression and dynamic preprocessing, feeds it to the SimLingo model for waypoint prediction, converts predictions to control commands using PID controllers and a kinematic bicycle model, and executes them on the QCar2 platform—all while generating natural language commentary explaining the vehicle's actions.
Methodology
Vision-Language-Action Architecture
The system employs the InternVL2-1B vision-language model with LoRA (Low-Rank Adaptation) adapters trained on the SimLingo checkpoint (epoch=013.ckpt). The model processes multi-modal inputs to generate driving actions:
- Visual Input: Camera images preprocessed into 448x448 patches with JPEG compression matching CARLA training data
- Spatial Input: Target waypoints converted to ego-centric coordinates using lookahead algorithm
- Language Input: Optional natural language instructions via interactive commentary window
- Output: Predicted waypoints, speed profiles, and natural language commentary
Control System Pipeline
The complete autonomous driving pipeline consists of five integrated components:
- Route Manager: Predefined waypoint routes with lookahead algorithm for target point selection
- Camera Processor: JPEG compression, dynamic preprocessing, and ImageNet normalization
- SimLingo Model: Vision-language inference predicting 2-second trajectory and speeds
- Control Converter: Lateral PID (Kp=3.25, Ki=1.0, Kd=1.0) and longitudinal linear regression
- QCar2 Interface: Kinematic bicycle model converting to forward velocity and turn angle
Natural Language Command Processing
The system supports high-level commands (HLC) through an interactive commentary window. Users can issue instructions like "Turn left at the intersection" or "Slow down and prepare to stop." The model switches to INSTRUCTION_FOLLOWING mode, incorporating the command into its prompt alongside visual and spatial inputs to generate appropriate driving behavior while maintaining safety constraints.
Experimental Results
Obstacle Avoidance Demonstrations
The following images demonstrate the system's ability to navigate obstacle-rich environments while processing natural language commands. Each scenario shows the ego vehicle, an interaction window for real-time command input, and commentary describing the vehicle's actions.
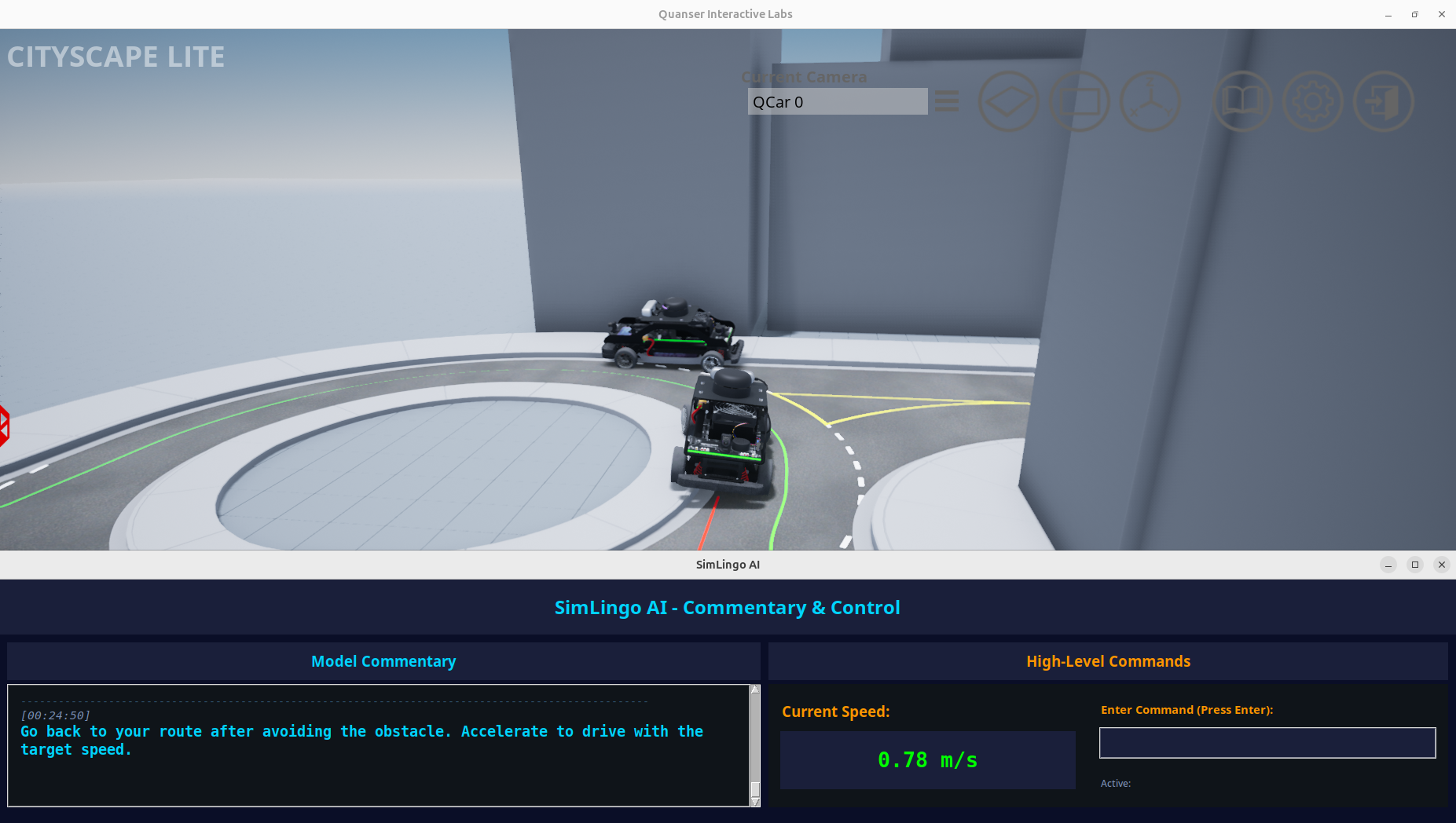
Figure 1: Roundabout obstacle avoidance scenario. The ego vehicle is approaching a roundabout with a car parked at the entrance, positioned slightly to the left of the desired green polyline route. The model's commentary output states: "Go back to your route after avoiding the obstacle. Accelerate to drive with the target speed." This demonstrates the system's ability to detect obstacles, plan safe avoidance maneuvers, and provide real-time natural language explanations of its driving decisions.
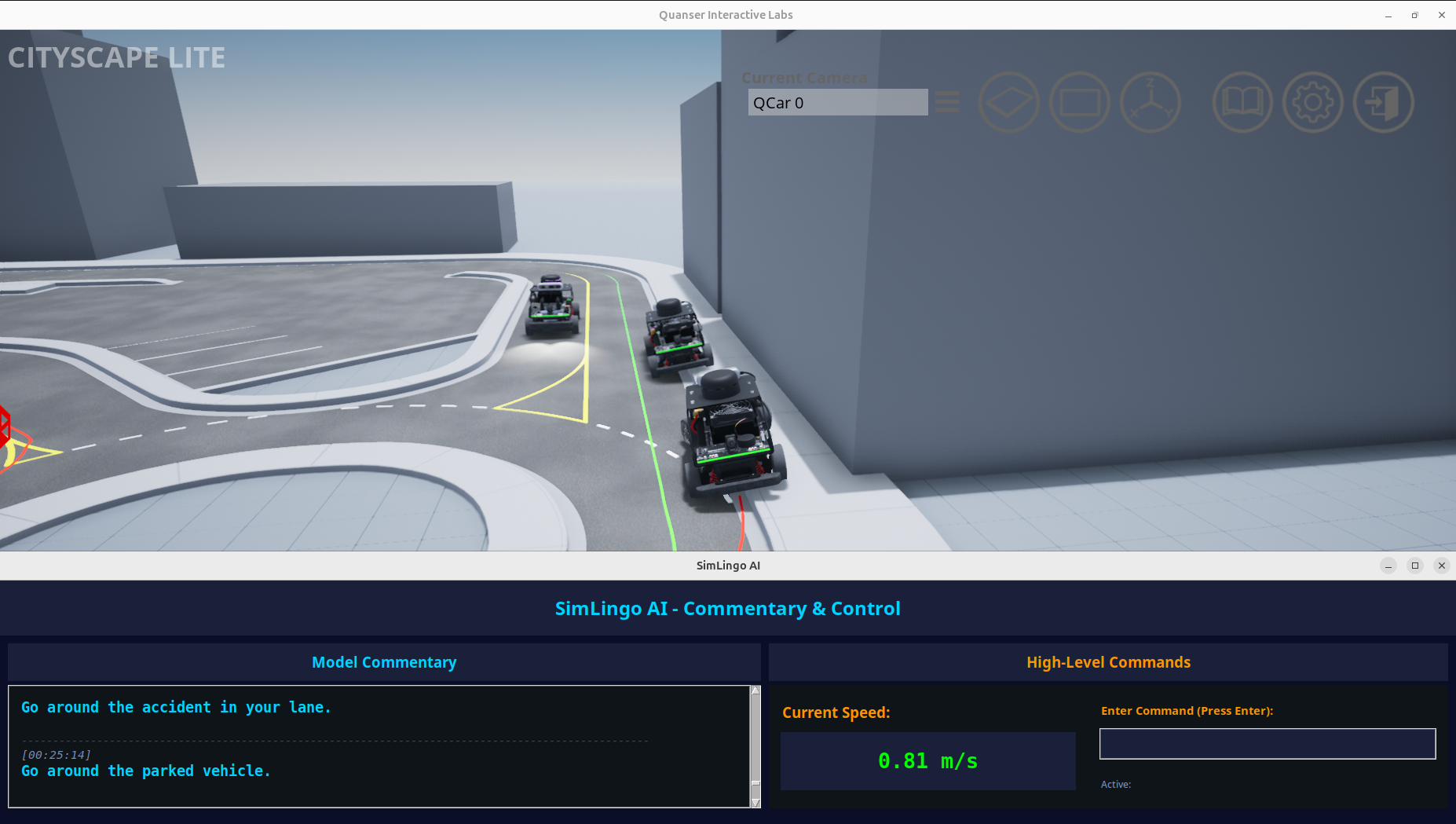
Figure 2: Complex multi-obstacle scenario. The ego vehicle approaches a parked vehicle on the curb while oncoming traffic is present, positioned slightly to the right of the polyline. The model generates two commentary outputs: (1) "Go around the accident in your lane" (a hallucination/false positive indicating the model requires fine-tuning for QLabs environment), and (2) "Go around the parked vehicle" (correct detection). This highlights both the system's perception capabilities and areas for improvement through domain-specific fine-tuning.
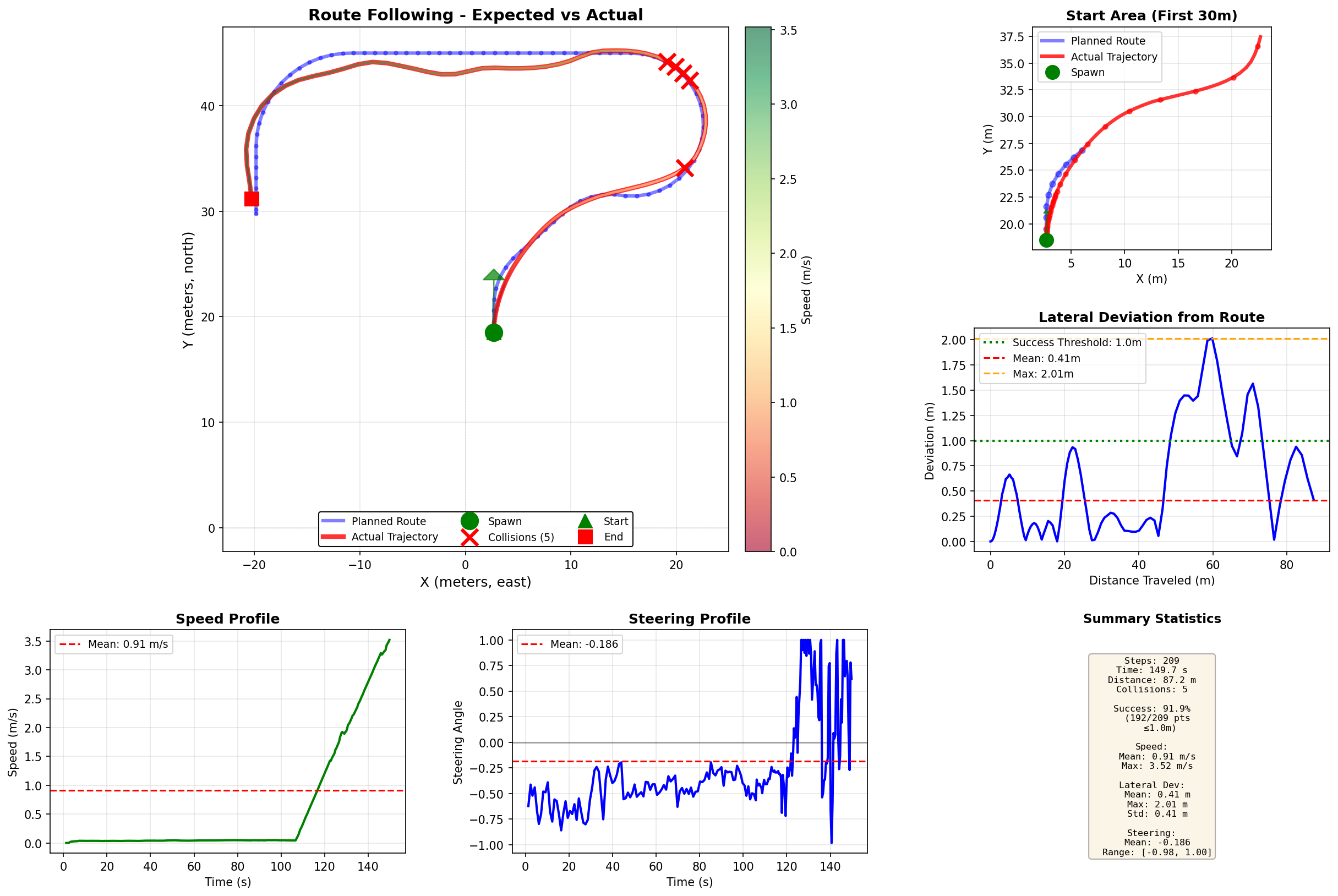
Figure 3: Trajectory comparison showing the expected route (blue polyline representing defined waypoints) versus the actual path followed by the vehicle (red line). The graph includes experimental statistics demonstrating the system's tracking accuracy and performance metrics across the complete test route.
Key Findings
- Vision-Language Integration: Successfully adapted SimLingo model from CARLA to QCar2 platform while preserving core AI capabilities
- Natural Language Understanding: Demonstrated ability to interpret and execute diverse natural language commands in real-time
- Trajectory Accuracy: Achieved precise waypoint following with minimal deviation from planned routes
- Real-time Performance: GPU-accelerated inference on RTX 5070 enables responsive control at practical driving speeds
- Explainable AI: Generated natural language commentary provides transparency into autonomous decision-making
Technical Contributions
VLA Model Adaptation
Successfully adapted SimLingo vision-language-action model from CARLA to QCar2 platform
Natural Language Control
Implemented high-level command interface for intuitive vehicle control via natural language
Integrated Pipeline
Developed complete autonomous driving pipeline from camera to control with real-time commentary
GPU Acceleration
Optimized inference for CUDA 12.8 enabling real-time performance on RTX 5070
Repository
QCar2 SimLingo Integration
GitHub Repository - 2025
Autonomous Driving, Vision-Language Models, Natural Language Processing