VLA Autonomous Driving
Fine-tuning a 957M parameter multimodal model for real-time vehicle control - MS Thesis
Vision-language-action (VLA) models trained in one simulator don't transfer to another. SimLingo, a state-of-the-art driving policy trained in CARLA's photorealistic environment, achieves only 4.7% route coverage when deployed directly in QLabs - a flat-shaded educational simulator with fundamentally different visual characteristics.
The thesis frames this as a distribution alignment problem: how do you adapt a 957M parameter model to a new visual domain with limited data, while maintaining real-time control at 4Hz on embedded hardware?
End-to-end pipeline: data collection → fine-tuning → inference → evaluation
The architecture threads a frozen visual encoder into a lightweight language model adapted with LoRA - keeping the pretrained driving knowledge intact while remapping visual representations to the new simulator's domain.
Camera images enter InternViT-300M (frozen visual encoder), pass through a projection layer, then feed into Qwen2-0.5B with LoRA adapters (17.6M trainable parameters). Thirty learnable query tokens extract route waypoints (20) and speed waypoints (10) from the LLM hidden states. The LLM serves as a feature aggregator, not a text generator - autoregressive output is unused.
With only 7,498 training frames, full fine-tuning would overfit and destroy the pretrained driving priors embedded in the base model. LoRA restricts updates to low-rank adapter matrices, preserving the model's existing knowledge of scene understanding and motion planning while adapting its visual-linguistic representations to QLabs' flat-shaded environment.
InternViT-300M was pretrained on a massive and diverse visual corpus. Freezing it entirely keeps low-level and mid-level visual grounding stable across training. Only the language reasoning pathway adapts - which is precisely where the sim-to-sim gap manifests as misinterpreted scene semantics rather than raw feature failure.
The training data was collected with instantaneous velocity derived from a single frame's odometry reading. Using multi-frame optical flow or temporal differencing at inference would introduce a distribution shift within the simulator itself - the model would see velocity signals it was never trained on. Single-frame estimation matches the training distribution exactly.


The visual domain gap: CARLA's photorealistic rendering (left) vs QLabs' flat-shaded graphics (right)
Key features
By the numbers
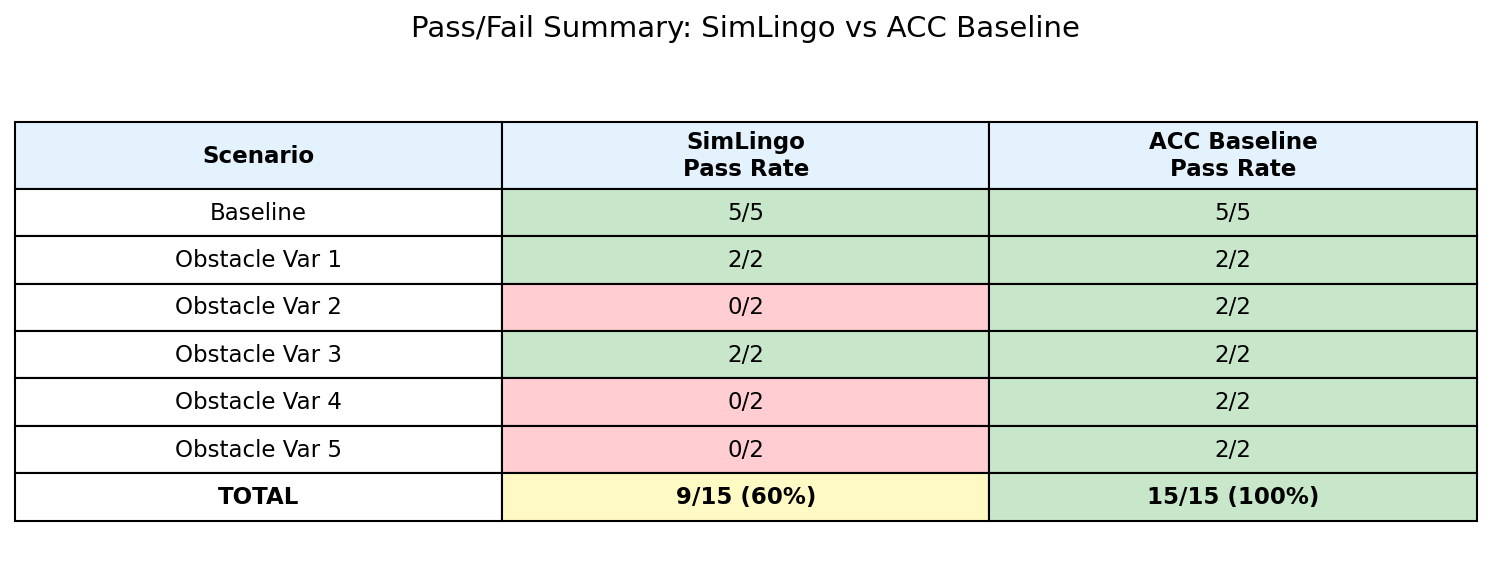
The biggest insight was that the 4.7% pre-trained performance wasn't a model problem - it was a distribution problem. LoRA fine-tuning with only 7,498 frames was sufficient to bridge the visual gap, which suggests that the pretrained model's driving knowledge is remarkably transferable once you align the input distribution.
The failure cases (curved sections at high speed with late obstacle visibility) point to limitations of single-camera perception, not the VLA architecture itself. If I were to extend this work, I'd explore multi-frame temporal context and evaluate transfer to the physical QCar2 hardware.